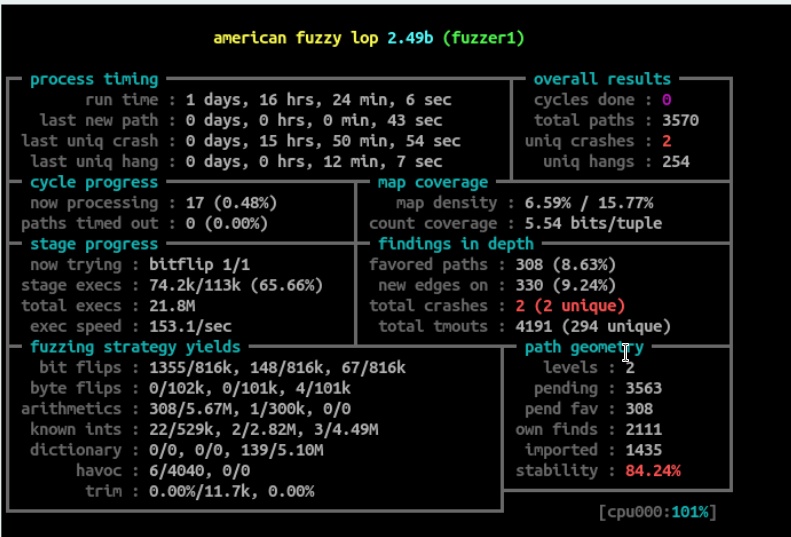
Feedback driven fuzzing (AKA Genetic Fuzzing) have been proven to be one of the most effective ways to find memory corruptions.
One of the best fuzzers out there is AFL which is created by lcamtuf (Michał Zalewski).
AFL can fuzz both open source applications using instrumentation which is very effective specially when using LLVM instrumentation, for closed source applications AFL runs in qemu mode which is very good, however I found some problems with some applications that I wanted to fuzz, I looked for other fuzzers and it didn't meet my needs like for example I wanted to fuzz some applications that doesn't exit after reading the file.
I also thought that it would be a good practice to write my own fuzzer, and I have been thinking about it for a while until Gynvael posted a video about it in youtube, he actually implemented a dump fuzzer and Genetic fuzzing in two of his videos which encouraged me to start writing my own.
I decided to use C++ and Qt Framework to implement the fuzzer since I have a good experience with both, and I knew that I could use the event based system to my advantage to gain some performance.
To implement the fuzzer I planned to use some existing libraries and applications to make it easier to get a first release, later I will replace those technologies with the ideas that I have in mind to make this fuzzer stand out.
The first problem was how to calculate the coverage, for that I used dynamo rio drcov module, I wrote a parser for the binary coverage files and a generator that generates the proper coverage file name for each fuzzed process.
Once the process exits it emits a signal "processFinished" (I am using QProcess) so I check inside the signal handler to see if the process exits normally or crashed, if it exits normally I start calculating the coverage and if the test cases caused the execution of more blocks I update the discovered blocks and add the test case to the input directory .. simple righ ;)
for Mutations I used radamsa which is a good mutator, instead of forking radamsa to generate test cases which means I have to run two processes at each iteration (radamsa and the fuzzed application), what I did is that for each test case I started radamsa in server mode and I keep reading the mutated data using a socket (not sure if this is actually faster than forking so I will check that later).
for forking the application, as I mentioned before I used QProcess and the way I did it is that I added a timer that calls a signal handler that runs that fuzzed application and feeds it the mutated data, I limit the maximum number of processes that are allowed to run in parallel, this approach is pretty fast and fully utilizes the availabe resources.
The GUI will be inspired by both microsoft minifuzz and AFL, the fuzzer will have a GUI (after all it's written in Qt) and may be in the future I will add a command line interface (which also can be done using Qt).
I will also add the ability to add custom coverage modules and custom mutators using plugins.
That's it for now, next I will start working to replace radamsa, then replace drcov with my own code that should be faster in calculating coverage, who knows may be at some point in the future I will add symbolic execution when the fuzzer is stuck.
For the updates you can follow me on twitter @fady_othman.